
The Dutch psychologist Adriaan de Groot doesn’t always get the same kind of recognition as other cognitive psychologists, his name often restricted to paragraph or two in psychology textbooks or a brief citation in the work of others such as Anders Ericsson, Alan Baddeley and John Sweller. Nevertheless, De Groot has been described as ‘the pioneer of cognitive psychology’ and was proclaimed the most influential Dutch psychologist ever by an independent panel that included Ericsson (De Groot died in 2006 at the age of 91). In his lifetime he’d worked as a high school teacher and an industrial psychologist for a railway company, but it’s his studies of chess players for which he’s most widely known (he was, himself, a passionate and highly skilled player).
His combined interests in chess and psychology converged when he began interviewing other players about the strategies they used during their games, beginning his investigations in the 1930s when still a student. He showed chess players a sample board and asked them to talk through their strategies as they decided on their next move. De Groot had assumed that expert players were more skilled at carrying out mental calculations, working out possible moves and their consequences, but what his interviews revealed was that skill at chess seemed to be more about memory and how it’s used. Chess is a highly complex game, especially at expert and grand master level. It’s estimated that there are around 1020 possible games of chess and that human players (as opposed to computers) will consider tens, if not hundreds, of positions before selecting a move. Only rarely will they think through to a win, lose or stalemate situation.
De Groot compared the performance of five grand masters and five expert players on choosing a move from a particular board position. He then asked them to think aloud and determine the types and number of moves they would consider. Surprisingly, perhaps, grand masters didn’t consider more alternative moves than experts but they did take less time to make their move. Independent raters also judged the final moves of the masters to be superior to the experts. Then, when participants were given a five second presentation of board positions from actual games and asked to reconstruct them from memory, grand masters were correct 91 percent of the time compared to 41 percent for experts. Crucially, however, when pieces were randomly arranged without any appreciation of chess rules, both groups performed equally bad.
Prior Knowledge
What appears to be happening is that the players are sifting through their memory of previous games and using their prior knowledge to plan their next move. Rather than creating solutions from scratch for every game, they are making use of the information they already have. It’s probable that these previous games are stored in the form of schemas, the positions on the board acting as cognitive cues that provide rapid access to them. But this is only effective if the board positions represent actual games. This rapid cue based access also places less strain on limited cognitive resources, enabling the player to cope with the current positions in a cognitively economic manner.
Experts, therefore, don’t necessarily have better memories or think faster than novices, but they are able to employ strategies that place less strain on working memory, while their problem solving strategies depend on the knowledge already available. In other words, the more we know, the less we have to think.
Experts differ from novices both in the structure of domain related knowledge (what they know about chess) and the ability to retrieve episodic domain-related information (recalling a previous chess encounter and board setup). It’s hypothesised this domain-specific information is stored in long-term memory as schemas. Generally, we assume that this information is accessed and rapidly transferred to short-term working memory, but Ericsson suggested that they may actually be utilising long-term working memory. Long-term working memory represents a unitary model of memory with no reference to different modalities (as in, for example, the components of Baddeley and Hitch’s working memory model). This means that all information is part of a schema and the individual elements defined by activation level. This activation level declines over time (following the temporal decay hypothesis) but is slower for information for which people are experts. This means that experts are are able to hold more information for longer and with fewer cognitive costs than novices.
Experts exhibit superior episodic memory for domain-typical information, possibly because of their ability to directly access long-term memory to rapidly and reliably encode and retrieve the information instead of maintaining it in short-term memory alone. Furthermore, Chase and Simon suggest that chunking also plays a role. Recurring patterns reflect a characteristic relationship between a set of a few chess pieces (such as attack and defence); when a chunk is recognised in a newly encountered board position, a ‘pointer’ is placed in short-term memory referencing the long-term representation of the chunk (reducing the effects of short-term capacity limitations). This chunking theory of expertise doesn’t assume there is direct storage of the memory trace in LTM but, rather, simply acts as a pointer to the ever-increasing store of larger chunks in LTM – experts have more chunks stored than novices. This would also explain the poor performance when the boards are set up randomly, because both novices and experts have fewer chunks to draw on.
There is, however, a downside. Experts superior recognition is often exaggerated for information related to the central goals within the domain. Experienced drivers, for example, use information stored in long-term memory to drive their car and arrive safely at their destination (their goal), but rarely recall much of the actually journey (unless something out of the ordinary occurs). One study, for example, found that computer programers asked to complete a coding task had worse incidental recall (information they weren’t required to recall) than novices for details of code. The experts payed greater attention to the goal structure (the end result) than the actual detail of the code. Similarly, Schmidt and Boshizen (1993) found that recall of patient information following a medical diagnosis task varied non-monotonically with the level of expertise, creating an inverted U. Participants with an intermediate level of expertise recalled more information about the patient than either those with more or less expertise. The poorer recall was attributed to the selectively and abstraction consistent with the use of schemas.
Implications for Learning
Long-term working memory was incorporated into Sweller’s Cognitive Load Theory in 2011 as a means to explain certain research findings linked to expertise reversal (see here for an explanation of the Expertise Reversal Effect). CLT didn’t initially refer specifically to models of memory beyond the limitations identified in terms of capacity and duration, and attention. It certainly drew on the information processing models of Broadbent (1958) and Atkinson and Shiffrin (1968) but when the latter’s unitary short-term memory component proved too simple to explain some empirical findings, the emphasis switched to Baddeley and Hitch’s multicomponent working memory model. More recently, researchers have attempted to apply CLT to Barrouillet’s Time Based Resource Sharing Model, which I’ve written about here. (Puma, Matton, Paubel & Tricot, 2018).
Long-term working memory, therefore, explains some findings from CLT research, but not others. For example, because LT-WM doesn’t recognise separate modality stores (such as the visuospatial sketchpad and phonological loop in the Baddeley and Hitch model) it is unable to explain the modality effect. It does, however, explain the redundancy of information for expert learners when presented in two sensory modalities. According to Puma and Tricot, ‘if learners are expert enough, then this information presentation activates the same schema and thus imposes twice the processing for the same result’ (Tindall-Ford, Agostinho and Sweller, 2020 p.46).
One of the most significant implications, however, is probably the role schemas play in people’s ability to rapidly process information. Furthermore, if schemas are activated directly in long-term memory via long-term working memory, there should be less load placed on short-term working memory, with its resource limitations (capacity and duration). This process then poses a potential dilemma highlighted by Cowan (2021), in that it has always been assumed working memory acts as a ‘front-end’, that information must first pass through a short-term or working memory store before it can take up relatively permanent residence in long-term memory. Both theories of long-term working memory and Cowan’s Embedded Processes Model (see figure 1), refer to direct activation of long-term memory via focus of attention (they are both generally considered unitary models, although Cowen’s model embeds processes within others). This wouldn’t rule out the possibility that some information is encoded directly into long-term memory, bypassing working memory altogether.
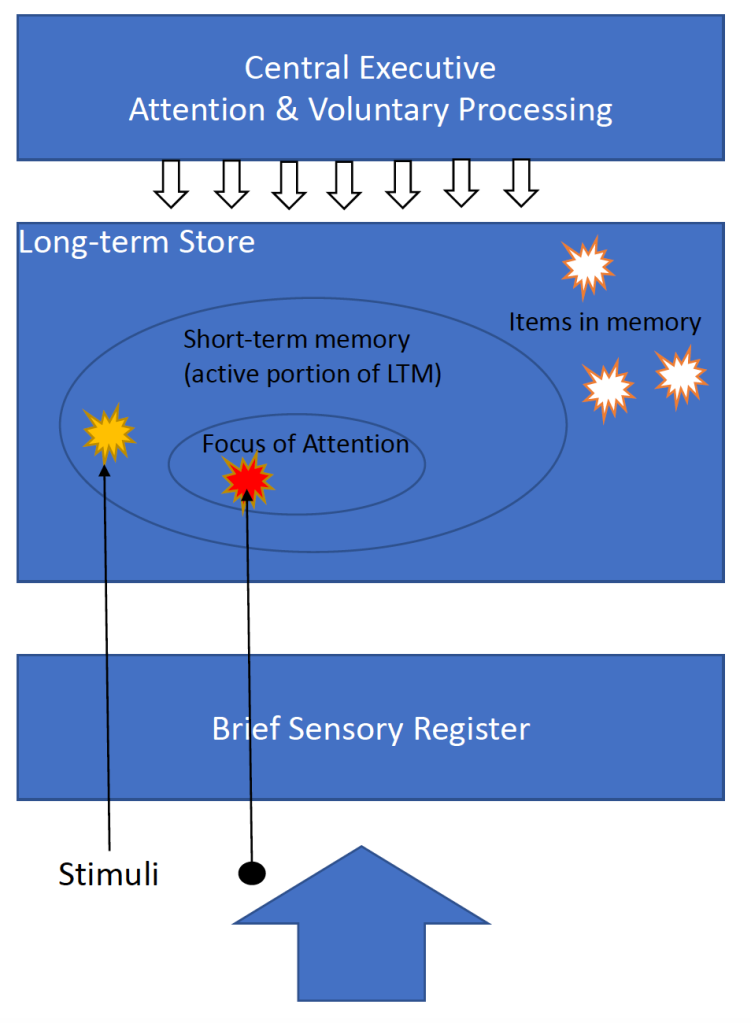
Regardless of the role of working memory, the development of expertise does appear, at least in part, to involve the construction of these knowledge schemas; the more we have at our disposal, the faster we can assimilate new information and recall what we already know. This also makes intuitive sense and seems to fit with our lived experience.




Leave a comment